E1M-X V2N-M1
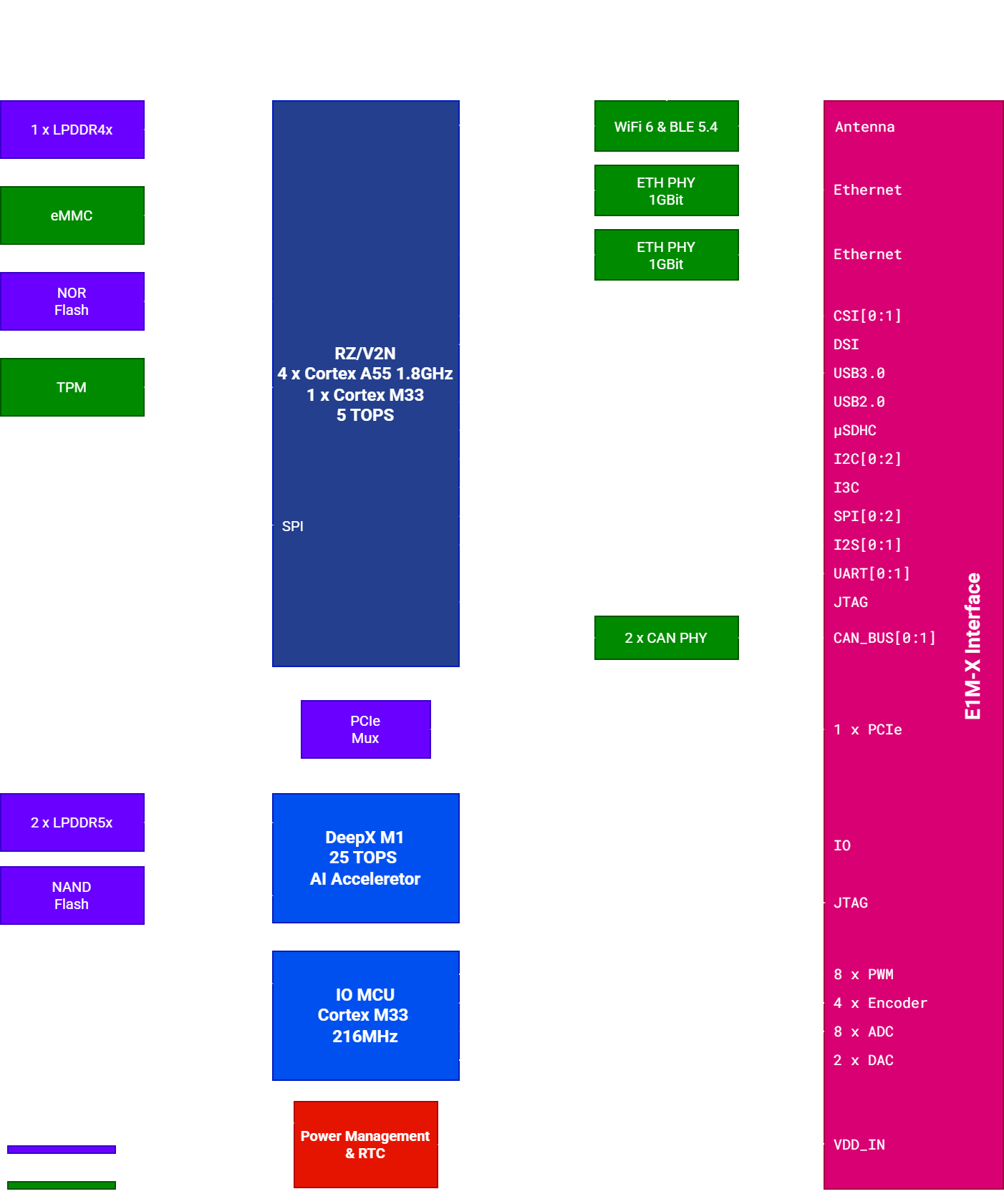
The E1M-X V2N-M1 combines the Renesas RZ/V2N processor with the on-module DEEPX DX-M1 NPU to deliver 25 TOPS of dense inference performance in the same 45 × 65 mm form factor as the base V2N.

Module variants
| SKU | Memory | Status |
|---|---|---|
E1M-V2M101 | 32 Gbit LPDDR4X + 32 Gbit eMMC + DX-M1 | production |
E1M-V2M102 | 64 Gbit LPDDR4X + 64 Gbit eMMC + DX-M1 | production |
At a glance
| Parameter | Value |
|---|---|
| Application core | Quad Arm Cortex-A55 @ 1.8 GHz (RZ/V2N) |
| Real-time core | Arm Cortex-M33 (RZ/V2N) |
| AI accelerator 1 | Renesas DRP-AI3 (4 TOPS dense) |
| AI accelerator 2 | DEEPX DX-M1 (25 TOPS @ 1.0 GHz) |
| Total AI throughput | 4 + 25 TOPS (dense) |
| Module dimensions | 65 × 45 × 5 mm |
| Form factor | E1M-X (45 × 65 mm), LGA |
| OS targets | Yocto Linux |
| Indicative price | $179 |
What's added vs the V2N base
V2N-M1 inherits the full V2N base module (see V2N) and adds:
| Component | Where + how |
|---|---|
| DEEPX DX-M1 NPU | On-module, PCIe |
M1_RESET | Renesas-side GPIO controlling DX-M1 reset (active-low) |
| 2 × PI3DBS12212A muxes | Switch PCIe routing between DEEPX and the E1M edge |
| 0.75 V DEEPX rail | DA9292 CH2 (disabled on V2N base; brought up by FW on M1) |
| 3 × TPS628640 bucks | DDR5/LPDDR rails for DEEPX (0x44 / 0x48 / 0x4F) |
Dual-accelerator architecture
| Accelerator | Performance | Strengths |
|---|---|---|
| DRP-AI3 | 4 TOPS dense | Low-latency, tightly coupled to the ISP |
| DEEPX DX-M1 | 25 TOPS dense | High-throughput, large-model support |
Workloads can be partitioned across both accelerators. A vision pipeline might run a lightweight detection model on the DRP-AI3 while a heavier classification or segmentation model runs on the DEEPX side.
DEEPX bring-up
Host firmware (or the kernel) must run a four-step sequence after the Renesas side boots and before the Linux kernel opens the PCIe device:
- Enable the 0.75 V DEEPX rail via the secondary PMIC's CH2.
- ACK-probe the three DEEPX TPS628640 instances at
0x44 / 0x48 / 0x4Fto confirm population. - Route the PCIe muxes to the DEEPX path with the PI3DBS12212A driver.
- Release
M1_RESETon RenesasPA6(active-low).
The chips/deepx_dxm1/ driver wraps steps 3-4 into a single deepx_dxm1_bring_up(&ctx, DEEPX_DXM1_DEFAULT_BOOT_US) call. Walk-through with code: docs/bring-up-v2n-m1.md.
DEEPX userland
The DEEPX silicon's userland API (libdxrt.so) is upstream at github.com/DEEPX-AI/dx_rt. The Yocto layer that brings it into your image is wired in meta-alp-sdk/conf/machine/e1m-v2m101-a55.conf and references github.com/DEEPX-AI/meta-deepx-m1.
ONNX models are converted to the .dxnn format using the DEEPX compiler; the workflow is model-family agnostic.
Drop-in upgrade from V2N
V2N-M1 shares the same E1M-X pinout and physical dimensions as the V2N base. Existing board designs work without modification. The only change required is software:
- Switch
som.skutoE1M-V2M101(orE1M-V2M102) in yourboard.yaml. The SoM preset'scapabilities:block declares bothdrp_aianddeepx_dx, so the loader compiles in both dispatchers; noinference.backend:knob to set (that field was removed in v0.6 follow-up cleanup — it's silicon-determined). - Open an inference handle per accelerator at runtime via
alp_inference_open(.backend = ALP_INFERENCE_BACKEND_DEEPX_DXM1)(or_DRPAIfor the on-die NPU). Two handles can dispatch concurrently to either NPU. - Ship a Yocto image built against
e1m-v2m101-a55.conf(includes the DEEPX kernel driver and userland).
Getting started
- Mount the E1M-X V2N-M1 on a compatible board.
- Flash the V2N-M1 Yocto image (DEEPX driver +
libdxrt.soincluded). - For M33 development, drop a
board.yamlwithsom.sku: E1M-V2M101and follow the Quick Start.
Resources
- Firmware quickstart — V2N-M1 bring-up
<alp/inference.h>— DEEPX dispatcher- Chip catalogue
- Industrial inquiries